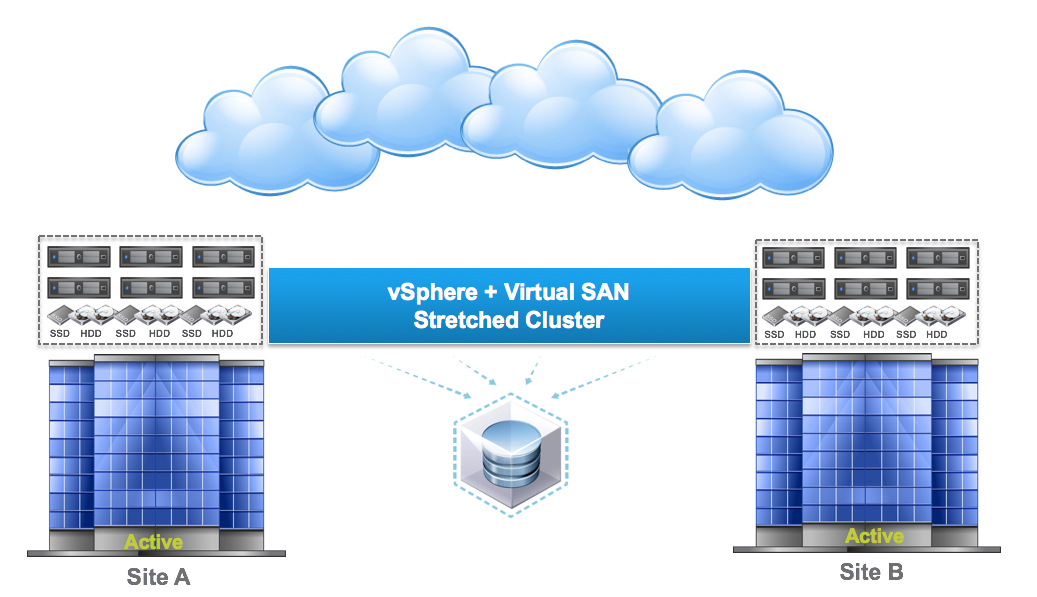
One of the most distinguishing features of VMware Virtual SAN 6.1 is the availability of stretched cluster deployment. The stretched cluster allows the Virtual SAN customer to configure two geographically located sites, while synchronously replicating data between the two sites. This provides high availability and protection against a single site failure.This VMware white paper examines the performance aspects of a Virtual SAN stretched cluster deployment. Specifically, it examines the overhead of synchronously replicating data across two geographical sites by bench marking against a regular, single site Virtual SAN cluster deployment.
Failure scenarios of a single hard disk and entire site failure are considered. The Virtual SAN stretched cluster can handle both failure scenarios robustly. The Virtual SAN stretched cluster architecture is different from how the regular (non-stretched, single fault domain) Virtual SAN cluster behaves. The following are the main differences.
1) Write latency: In a regular Virtual SAN cluster, mirrored writes incur the same latency. In a stretched Virtual SAN cluster, the write operations need to be prepared on the two sites. Therefore, one write operation needs to traverse the inter-site link, and thereby incur the inter-site latency. The higher the latency, the longer it would take for the write operations to complete.
2) Read locality: The regular cluster does read operations in a round robin pattern across the mirrored copies of an object. The stretched cluster does all reads from the single object copy available at the local site.
3) Failure: In the event of any failure, recovery traffic needs to originate from the remote site, which has the only mirrored copy of the object. Hence, all recovery traffic traverses the inter-site link. In addition, since the local copy of the object on a failed node is degraded, all reads to that object are redirected to the remote copy across the inter-site link.
Virtual SAN Stretched Cluster Setup
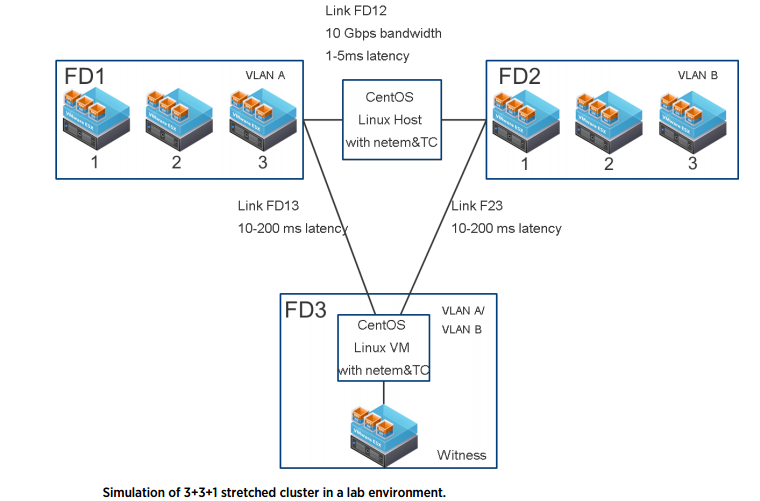
Best Practices
Impact of Inter-Site Latency and Bandwidth
One of the major distinguishing factors of a Virtual SAN stretched cluster deployment is the active/active site configuration and a metropolitan area link between the two sites. The performance of the Virtual SAN stretched cluster largely depends on bandwidth and latency available on this inter-site link. It is recommended that the inter-site link have preferably 10 Gbps bandwidth. Higher inter-site bandwidth may be required for larger sized clusters. This bandwidth is required mainly to accommodate recovery from a failure scenario. In the event of any failure, the replicas in the failed node must be recreated from the data available on the other site. In case of a single HDD failure, recovery traffic could be very high. In the experiments with site failure, recovery peak traffic was measured at over 2 Gbps. In terms of inter-site latency, higher inter-site latency affects the latency of write I/O transactions. The experiments show that with DVD Store, the Virtual SAN stretched cluster can sustain the overhead of 5ms latency without much impact to the benchmark performance. However, a 5ms inter-site latency does impact the write latency manifold when compared to a regular Virtual SAN deployment. It is recommended to limit inter-site latency to the order of 1ms, unless customer applications can tolerate high write latency.
Resource Sizing for Stretched Virtual SAN Cluster
In the event of site failure, all virtual machines start running on one site. Therefore CPU, memory, and cache resources must be overprovisioned to accommodate the failure event. Customers who require sustaining performance during site failure must ensure the admission control policy in vSphere HA is set so that the site resource utilization does not exceed 50%.
Performance During Failure Recovery
Recovery from a failure imposes significant stress on the Virtual SAN stretched cluster because the cluster needs to handle virtual machine I/O requests and recovery traffic at the same time. Virtual SAN design aims to balance the twin goals of fast recovery to ensure no data loss, and minimal impact to virtual machine I/O traffic. Testing shows that in the most common failure scenarios, such as HDD failure and site failure, the recovery traffic does not affect virtual machine I/Os significantly. Striking a balance between the two may depend on the customer’s specific setting. While the Virtual SAN software stack is designed to achieve an excellent balance, fine tuning the priorities of the recovery traffic and virtual machine I/O traffic might be necessary in very specific cases to achieve the best performance when the customer desires faster recovery or lower impact to virtual machine I/Os during recovery. The following configurable tuning option is provided for this purpose.
#esxcfg-advcfg -g /VSAN/DOMResyncDelayMultiplier
Value of DOMResyncDelayMultiplier is 6
#esxcfg-advcfg -s /VSAN/DOMResyncDelayMultiplier
A higher value of DOMResyncDelayMultiplier delays recovery traffic, making the recovery process longer but less intrusive to virtual machine I/O traffic. Caution must be exercised while changing this flag because higher values may make recovery very time consuming. Similarly, a lower value may make recovery traffic very disruptive. There could be extreme failure scenarios such as disk group failure (caused by SSD failure). Such a failure could cause a heavy volume of recovery traffic because of a large volume of data objects in the failed disk group; these objects now need to be backed up. HDD performance is on the critical path of these scenarios. Therefore, if such failure scenarios are foreseen, one remedy is to design the cluster with higher RPM HDDs that can sustain higher random I/O performance.
Conclusion
This white paper examines the various performance overheads that can exist in the Virtual SAN stretched cluster design. Testing shows that the Virtual SAN stretched cluster provides protection from site failure without introducing a significant performance penalty. This paper also describes the performance of the cluster under several failure scenarios. Testing shows that the Virtual SAN stretched cluster can adequately recover from site failure and balance recovery traffic with virtual machine I/O traffic.
Source: VMware White Paper
