Question: Can you explain me any major issue that you fixed in VMware Infrastructure? How you handle that situation? Can you list the steps that you followed to fix that problem?
Answer: It’s long back that I wrote the post for real time scenarios and today going to help you guys with one of common Interview question for this “Thanks Giving Day”. It’s always good to pick Storage related issues which creates high impact for both Phyiscal & VMware Infrastructures. I’m going to take the scenario of couple of VMs’ are not responding including vCenter Server which is also running as Virtual Machine.
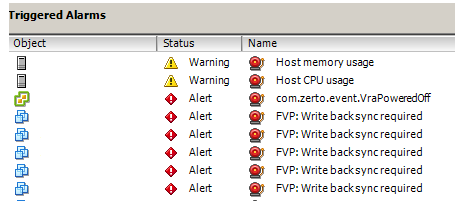
You can start the narration like – you got a call from Helpdesk about some VM’s are inaccessible in the vCenter server. When you connected to the vCenter server, you can’t access the console of VM’s as they stuck at black screen. From the screenshot it’s clear that, CPU & Memory usage is high for couple of hosts in the Cluster. You want to understand the reason for CPU & Memory utilization on the ESXi hosts and ran the “esxtop” command to know which VM/process creating more CPU/Memory utilization. If you are new to esxtop, then follow this article to know the usage of this command. As the issue is related to couple of virtual machine’s only then you downloaded vmware.log file to understand more about this issue from VM’s point of view. You notice that there is some latency to download the log files. While this issue is running, vCenter VM went to unresponsive state which makes the situation more worse. From the attempt of esxtop & vwware.log there is not much information to extract and management wants you to fix the vCenter VM issue first. Also SQL DB server also running as Virtual Machine which is holding vCenter & Update Manager DB’s. Also you installed PernixData (acquired by Nutanix) to improve storage I/O Performance for VM’s. These factors make the situation complex and below diagram helps you to understand the scenario in better way.
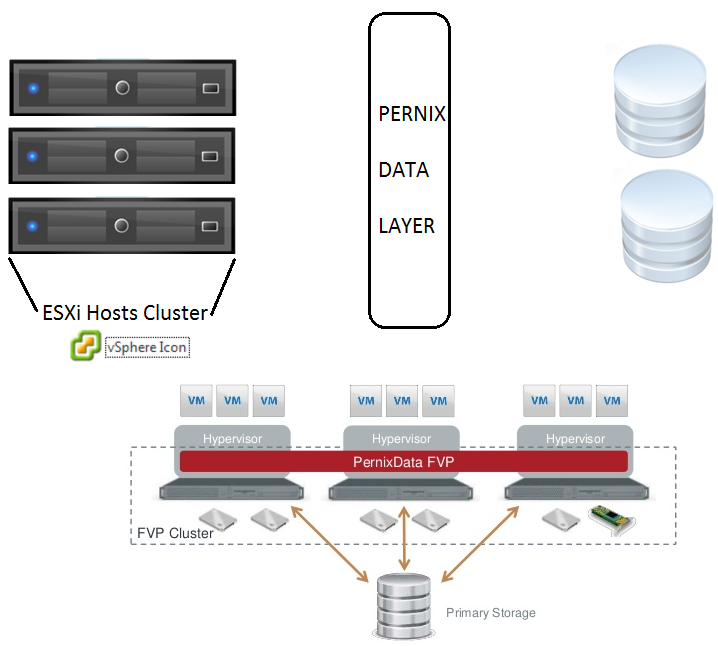
Now let’s talk about resolution step by step and how you found the issue with Storage. Help desk reported that another set of VM’s are not reachable in the network and they are hung at black screen when they opened the VM console from making direct connection to ESXi server. It means issue is really growing and impacting more business functions like SharePoint, Exchange, Citrix, Finance Applications … etc. Management declared this as MI (Major Incident) and requested you to join the bridge call along with other Technical teams like Storage, Network & Incident escalation managers. This is going to be collaboration effort rather than you fix this issue alone from VMware team. As there was latency to download the file and black screen for the VM console brings your attention to Storage related problems. esxtop has specific switches to understand storage related problems and check this article to know more details. For this escalation you need to know KAVG & DAVG values and thresholds as listed below.
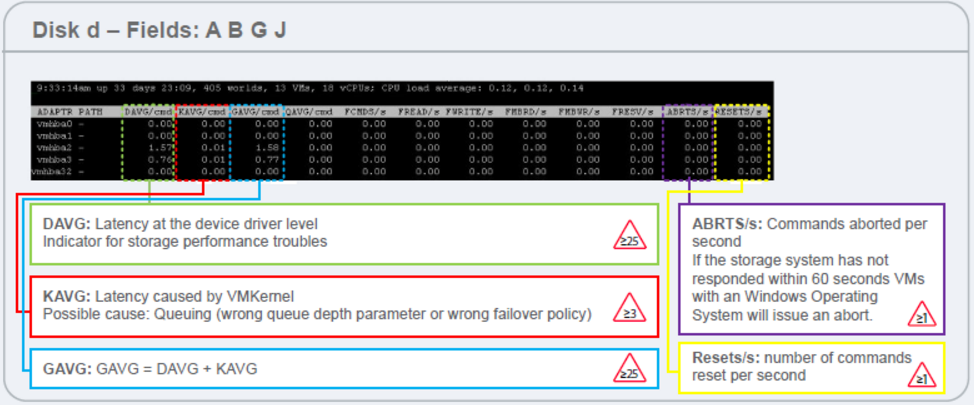

So from your troubleshooting it’s clear that there is ongoing Storage related problem in the Infrastructure which shows in esxtop and VM consoles are with black screen. You requested Storage team to validate the VNX configuration and performance to make sure they are also seeing any alerts or issues from their side. They came back quickly with an update that ALL stats are looking good for read & write operations. Management asking what is the problem and you are confident that there is some Storage issue but they can’t see in VNX side. So you requested the Storage team to give some recommendations and they comeback with a plan that, they are going to try to switch the Storage Processor from A to B. They executed this plan with management approval but there is no change in the situation. Later they want to try to reboot storage processors one by one but it has major impact if they can’t come online after reboot. Management agreed as ALL the production VM’s are down at that time. Storage team finished rebooting both processors successfully in 1 hour but that didn’t change anything in the VM’s status. Which means Storage team performed all the Troubleshooting including rebooting the SPA & SPB. Now management wants to know next action plan from VMware Infrastructure.
You are confident that there is Storage problem but VNX looks good then there should be a problem with another Storage layer which is Pernixdata. Upon investigating more from Pernixdata process – you found that there are lot of pending I/O jobs waiting at one of ESXi host server. You killed the pernix process on that specific host which brought the services online to normal state. One the VM’s became normal, you recommended the Management to perform clean ESXi reboot to avoid any immediate potential outage to the Production. They agreed for it and clean reboot performed for each ESXi host and conference call got closed after validating the Applications from the end users. (UAT – User Acceptance Test)

Resolution: Pernixdata helps to improve the Storage I/O performance by offloading that service to ESXi host local cache, however in this situation it’s holding lot of jobs which created above situation. By killing pernix process from ESXi host console and clean ESXi reboot brought the situation to normal state. Hope this helps you to answer Interview questions in better way and be social to share the knowledge.
