Question: What is HCI (Hyper-Converged Infrastructure) and how to manage VMware Infrastructure when there is HCI solution deployed like Nutanix (for this scenario). What are the commands to run against the cluster to check the health status? Have you ever run the upgrades for Control VM (AOS), Prism Central (PC – like vCenter), BMC/BIOS & Hypervisor? Can you explain the responsibilities to configure/manage the Nutanix based clusters?
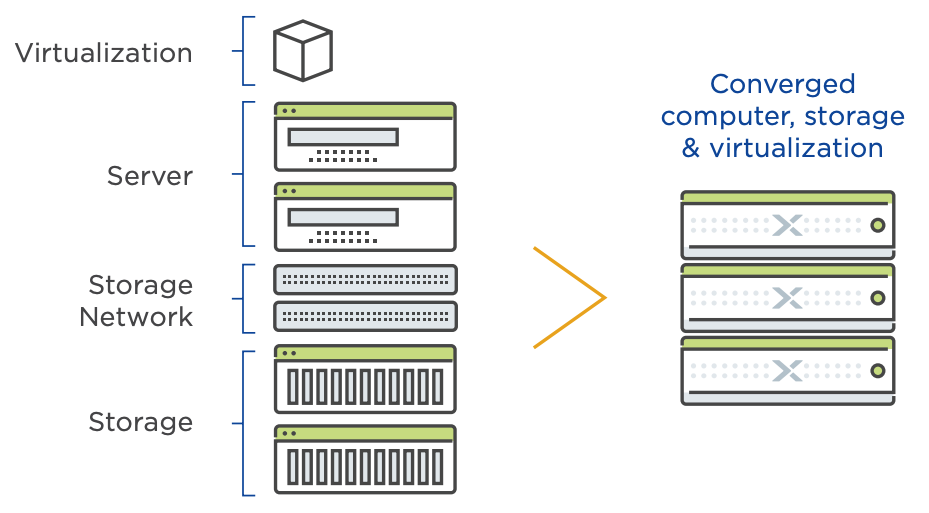
Answer: HCI aka Hyper-Converged Infrastructure became a turn-key solution and migrations from Traditional Infrastructure to HCI based solutions. Legacy infrastructure—with separate storage, storage networks, and servers—is not well suited to meet the growing demands of enterprise applications or the fast pace of modern business. The silos created by traditional infrastructure have become a barrier to change and progress, adding complexity to every step, from ordering to deployment to management. New business initiatives require buy-in from multiple teams, and IT needs must be predicted 3-to-5 years in advance. As most IT teams know, this involves a substantial amount of guesswork and is almost impossible to get right.
Hyper-converged infrastructure combines common datacenter hardware using locally attached storage resources with intelligent software to create flexible building blocks that replace legacy infrastructure consisting of separate servers, storage networks, and storage arrays. Nutanix converges the entire data center stack, including compute, storage, storage networking, and virtualization. Complex and expensive legacy infrastructure is replaced by Nutanix Enterprise Cloud OS running on state-of-the-art, industry-standard servers that enable enterprises to start small and scale one node at a time.
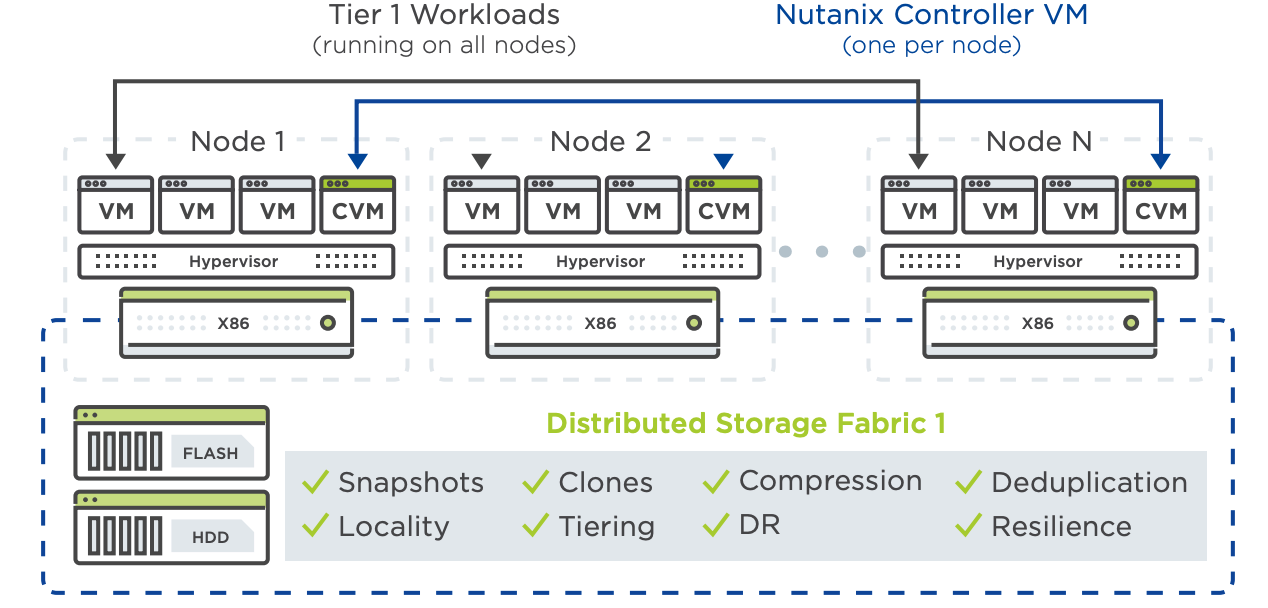
Each server, also known as a node, includes Intel-powered x86 or IBM Power hardware with flash SSDs and HDDs. Nutanix software running on each server node distributes all operating functions across the cluster for superior performance and resilience. The Acropolis Distributed Storage Fabric simplifies storage and data management for virtual environments. By pooling flash and hard disk drive storage across a Nutanix cluster and exporting it as a data store to the virtualization layer as iSCSI, NFS, and SMB shares, DSF eliminates the need for SAN and NAS solutions. A key concept for HCI is using SSD disks for hot data (active) and HDD disks for cold data (non-active).
Acropolis Distributed Storage Fabric joins HDD and SSD resources from across a cluster into a storage pool.
Enough of theory and let me help you with Nutanix Administrator useful commands for day to day operations. The key aspect of HCI is to make sure the storage online during the maintenance window or for any node/disk/chassis failures. AOS (Operating System) on Control VM requires frequent upgrades to get the newer feature sets and 1-Click upgrade is a famous selling point for the Nutanix Sales campaign. LCM (Life Cycle Manager) is a 1-Click tool to upgrade the BMC/BIOS and other devices firmware like LSA Controller, Disks & SATADOM. Prism Central is another Virtual Machine to be deployed in the Infrastructure like vCenter and always keep the Prism Central at the higher version than your Prism Element Clusters. (This point helps to make you real-time Nutanix Administrator). You can explain about some theory from above HCI notes and follow by below commands, will give the confidence for the Interview panel to select you for Nutanix Administrator jobs. Make sure you stress the point of AOS upgrade failures with /home full, Failed SATADOM replacement, CVM rescue, Nutanix Files, Async DR, NearSync, Metro Clusters & shutdown token failed to release from CVM terms to keep the discussion more real-time and promote discussion from theory to practical knowledge.
svmips && hostips && ipmiips - Display all the IP's in the clustercluster status | grep -v UP - Display the status of the services in Control VMnodetool -h 0 ring - Display the storage stack is online or notncli host list - Display the hypervisors listncli cluster get-redundancy-state - Display the Redundancy Factor valueallssh date - Display the date on ALL the Control VM'shostssh date- Display the date on ALL the Hypervisorsncli cluster info - Display the Cluster details (number of nodes - cluster ID - VIP)ncli ms list - Display the Hypervisor versionallssh ntpq -pn - Display the NTP statsncc --version - Display the Nutanix Cluster Check (NCC) versionncc healthchecks run_all - Run the Nutanix Health Checksncc log_collector run_all - Run the Nutanix logs collection (Logbay is the future tool)
SAMPLE OUTPUT FROM NUTANIX CLUSTER - THIS EXAMPLE HELPS YOU TO UNDERSTAND THE COMMANDS ONLY nutanix@NTNX--A-CVM:10.xx.xx.176:~$ svmips && hostips && ipmiips 10.xx.30.176 10.xx.29.176 10.xx.28.176 nutanix@NTNX--A-CVM:10.xx.xx.176:~$ cluster status | grep -v UP 2019-05-04 16:25:26 INFO zookeeper_session.py:135 cluster is attempting to connect to Zookeeper 2019-05-04 16:25:26 INFO cluster:2642 Executing action status on SVMs 10.xx.30.176 n2019-05-04 16:25:26 INFO cluster:2755 Success! The state of the cluster: start Lockdown mode: Disabled CVM: 10.xx.30.176 Up, ZeusLeader nutanix@NTNX--A-CVM:10.xx.xx.176:~$ nodetool -h 0 ring Address Status State Load Owns Token 10.xx.30.176 Up Normal 78.83 MB 100.00% 00000000VIxeuKCNP8v1koBev1UVdCAQ9TmNo7GlyXQtpS6Xaxjm3kIYf3BD nutanix@NTNX--A-CVM:10.xx.xx.176:~$ ncli host list Id : 00058751-8a31-a11b-0000-00000000e3da::3 Uuid : 19878e31-0ff7-4f72-be10-d480fc8706ff Name : NTNX-SERIAL-A IPMI Address : 10.xx.28.176 Controller VM Address : 10.xx.30.176 Controller VM NAT Address : Controller VM NAT PORT : Hypervisor Address : 10.xx.29.176 Hypervisor Version : Nutanix 20170830.184 Host Status : NORMAL Oplog Disk Size : 200 GiB (214,748,364,800 bytes) (0.5%) Under Maintenance Mode : null (-) Metadata store status : Metadata store enabled on the node Node Position : Node physical position can't be displayed for this model. Please refer to Prism UI for this information. Node Serial (UUID) : OM162S010412 Block Serial (Model) : 16SM52340075 (NX-6155-G5) nutanix@NTNX--A-CVM:10.xx.xx.176:~$ ncli cluster get-redundancy-state Current Redundancy Factor : 1 Desired Redundancy Factor : 1 Redundancy Factor Status : kCassandraPrepareDone=true;kZookeeperPrepareDone=true nutanix@NTNX--A-CVM:10.xx.xx.176:~$ allssh date ================== 10.xx.30.176 ================= Sat May 4 16:25:56 UTC 2019 nutanix@NTNX--A-CVM:10.xx.xx.176:~$ hostssh date ============= 10.xx.29.176 ============ Sat May 4 16:25:59 UTC 2019 nutanix@NTNX--A-CVM:10.xx.xx.176:~$ ncli cluster info Cluster Id : 00058751-8a31-a11b-0000-00000000e3da::58330 Cluster Uuid : 00058751-8a31-a11b-0000-00000000e3da Cluster Name : Diehard Cluster Version : 5.10.3.1 Cluster Full Version : el7.3-release-euphrates-5.10.3.1-stable-655d4def34bf18785782f2adb8cdd5f8457d1fe3 External IP address : Node Count : 1 Block Count : 1 Shadow Clones Status : Enabled Has Self Encrypting Disk : no Cluster Masquerading I... : Cluster Masquerading PORT : Is LTS : true External Data Services... : Support Verbosity Level : BASIC_COREDUMP Lock Down Status : Disabled Password Remote Login ... : Enabled Timezone : UTC NCC Version : ncc-3.7.0.2 Common Criteria Mode : Disabled Degraded Node Monitoring : Enabled nutanix@NTNX--A-CVM:10.xx.xx.176:~$ ncli ms list Name : 10.xx.29.176 Uuid : dce5b69a-5905-41b9-97bf-a32c5c4d0b45 Hypervisor Type : AHV Access URL : qemu+ssh://10.xx.29.176/system User Name : root Password : **** Hypervisor Version : el6.nutanix.20170830.184 nutanix@NTNX--A-CVM:10.xx.xx.176:~$ allssh ntpq -pn ================== 10.xx.30.176 ================= remote refid st t when poll reach delay offset jitter ============================================================================== *10.xx.1.20 69.164.213.136 3 u 735 1024 377 0.542 0.584 0.186 127.127.1.0 .LOCL. 10 l 9d 64 0 0.000 0.000 0.000 nutanix@NTNX--A-CVM:10.xx.xx.176:~$ ncc --version 3.7.0.2-3a444087 nutanix@NTNX--A-CVM:10.xx.xx.176:~$ ncc health_checks run_all +------------------------------------------------------------------------------------------------------+ | Type | Name | Impact | Short help | +------------------------------------------------------------------------------------------------------+ | M | cassandra_tools | N/A | Plugins to help with Cassandra ring analysis | | M | config_based | N/A | All config based plugin | | M | fix_failures | N/A | Fix failures | | M | hardware_info | N/A | Plugin to get or update node hardware information | | M | health_checks | N/A | All health checks | | M | help_opts | N/A | Show various options for ncc. | | M | log_collector | N/A | Collect logs on all CVMs. | | M | performance_checks | N/A | This module performs various performance checks on the cluster. | | M | pulsehd_collectors | N/A | Plugin to start the insights collectors | | M | upload_to_ftp | N/A | Uploads a file to SFTP/FTP server | +--------------------------------------------------------------------------------------------------+
“Be social and share this on social media, if you feel this is worth sharing it”
